🍦 Intersectional AI A-to-Z & FAQ
These glossaries of terms for Intersectional AI A-to-Z are a great place to get started. By all means they're only limited examples of definitions for complex ideas. They put in conversation the technical aspects and social aspects of AI systems by interweaving definitions found in disparate fields. They try to show the complexity of the topic from many angles, while breaking down the concepts into plain language. The goal is that a common vocabulary will allow more people to join the key conversations about AI's futures. Please chime in, ask questions, help make these definitions better! These glossaries would not be possible without the careful thought from other glossaries and readings which inform it. See below for references and resources.
"'[A]rtificial intelligence' means lots of things, depending on whether you're reading science fiction or selling a new app or doing academic research."1
When defining and talking about AI we have to be cautious as many of the words that we use can be quite misleading. Common examples are learning, understanding, and intelligence.2
AI terms are easy to mix up. AI is a subset of the field of computer science. Within it, machine learning is currently a commonly used techniqueand includes a variety of practices within it, like deep learning and neural networks. Almost all of these make use of work from the highly related field of data science.
"it's often the way the technology is being used, rather than the technology itself, that determines whether it is appropriate to call it AI or not."2
Shane, Janelle. 2019. You Look Like a Thing and I Love You. Little, Brown and Company.
University of Helsinki, Minna Learn. Elements of AI
Terms
|Artificial intelligence (1)|Artificial intelligence (2)|Bias & variance|Bias, implicit & systemic|Confidence interval|Codes of conduct|Data cleaning|Data colonialism|Datasheets|Embedding|Feature extraction| FLOSS|GPT|GAN|Global majority|Heteronormative|Intersectionality|Justice, transformative|K-Means & K-NN|Lynn Conway|Machine learning|Model|Neural network|Opacity|Protocol|Peer-to-peer|Queer OS|Racialization|Regression & classification|Supervised & unsupervised, Sustainability|Transformer|Uncertainty|Values, vectors, variables|(bag of) Words|X (input)|Y (output)|YOLO|Zero-shot learning|Zines
A is for artificial intelligence
Artificial intelligence (1)
AI colloquially refers to various systems that look for patterns in provided data. These can appear from the outside similar "human" abilities such as "understanding" or "seeing." But these can be achieved through many different systems that vary widely from simple calculation a programmer would not call AI to complex programs that search for patterns without being given directions in advance. AI systems are often made up of multiple components of machine learning tasks and other techniques.
Artificial intelligence (2)
There is no agreed definition of AI, but in general the ability to perform tasks without supervision and to learn so as to improve performance are key parts of AI.3 Even AI researchers have no exact definition of AI. The field is rather being constantly redefined when some topics are classified as non-AI, and new topics emerge.2 No matter their context or complexity, AI tools are always socio-technical systems, meaning they are designed, operated, and influenced by humans, rather than entirely autonomous, neutral systems.
University of Helsinki, Minna Learn. "Ethics of AI."
B is for bias
Bias & variance
In a machine learning problem, bias is the technical definition for when a model is underfit to the problem as defined by designers, meaning it cannot find the pattern in the data as expected. This happens when there is not enough, or not representative enough, data used to train it. Meanwhile variance, or overfit, is when a model overstates a pattern, overcomplicating the relationships in the data based on the creator's expected outcome. As bias decreases, variance increases, and vice versa. Other trade-offs include accuracy vs interpretability, complexity vs scalability, domain-specific knowledge vs data driven, better algorithm vs more data.4
Bias, implicit & systemic
Bias cannot be 'removed' entirely from algorithmic systems, from analog systems, nor from individuals — because "there is no way to create something without some intention and intended user in mind."5 Acknowledging implicit bias helps account for its existence and address its root causes.
"Implicit bias, also known as hidden bias, refers to the numerous ways in which we organize patterns 'thus creating real-world implications.' Exposure to structural and cultural racism has enabled stereotypes and biases to penetrate deep into our psyches. Implicit bias is one part of the system of inequity that serves to justify racist policies, practices and behaviors that persist in mainstream culture and narratives. Current research on implicit bias also provides some promise that individual neural associations can be changed through specific practices (debiasing). If those biases can be changed at the individual level, by definition, they can be changed at the societal level, given sufficient will and investment. Since some biases are unconscious, it may contribute to individuals shirking responsibility rather than actively disrupting the behavior. It is critical for implicit bias to be discussed in the context of how bias, racism, and privilege operate together and systemically." – Racial Equity Tools, via Studio Pathways Glossary6
Implicit and systemic biases are embedded in and are often amplified by digital systems, because computation replicates, speeds up, and compounds human decision-making. Unfortunately, "tech fixes often hide, speed up, and even deepen discrimination, while appearing to be neutral or benevolent when compared to the racism of a previous era." 5
"Codes are both reflective and predictive." 5 Bias is not the whole story; it merely points to preexisting systemic inequality, highlighted by classification thinking used in computation. "The tendency to focus on the issue of bias in artificial intelligence has drawn us away from assessing the core practices of classification in AI, along with their attendant politics." 7
Rajati, M.R. 2021. Lecture. Machine Learning for Data Science, USC, Los Angeles. June 2021.
Benjamin, R. (2019). Race After Technology: Abolitionist Tools for the New Jim Code. Polity.
Crawford, K. (2021). Atlas of AI: power, politics, and the planetary costs of artificial intelligence. Yale UP.
C is for codes & confidence
Confidence interval
A range of numbers that helps describe how uncertain an estimate is. Any confidence interval has a high (e.g. 95%) chance of containing the "true" value (that is, the accurate answer to the question being asked). So the bigger the interval, the more uncertain and the more doubt. Confidence intervals are used in statistics and in AI to determine a model formula's reliability. Classically presumes a hidden but "true" unknown value that is independent of the model (and this is not always the case of course). Unfortunately, uncertainty remains inherent in prediction and difficult to comprehend in models, even for researchers who create them.8
D'Ignazio, C. and Klein, K. 2020. Data Feminism. MIT Press.
Codes of conduct
Usually written together by a group, these guidelines outline expectations for behavior and procedures for when members of a community don't meet those expectations. While some argue for structureless, free-speech zones online, many counter that a lack of guidelines highlights power dynamics existing in broader culture.9
Dunbar-Hester, C. 2020. Hacking Diversity. Princeton UP.
D is for data
Data cleaning
Data does not come in ready to go, it must be preprocessed. Sometimes called cleaning, this process involves checking and modifying data before analyzing it or using it for training a system. Preprocessing includes many adjustments that can affect the outcome, including selecting a subset of data (sampling), standardizing and scaling it in relation to a baseline (normalization), handling missing data and outliers with decision trees (which Adrian MacKenzie calls "affiliated with arbitrariness"),10 as well as feature creation and extraction (discussed in Feature extraction). The transformation of real-world information into data is never a neutral process but relies heavily on the conditions and goals of the research in context. For more on preprocessing data, see "A Critical Field Guide to Working with Machine Learning Datasets: Transforming Datasets."11
Data colonialism
Data are values that can be assigned to a thing and can take a variety of forms.12 How you think about and utilize the information is what turns it into data. Sensing, observing, and collecting are all acts of interpretation that have contexts, which shape the data. Data do not just exist but have to be generated, through sensors and human effort.11 The human labor to produce and modify data can become another form of extraction and exploitation, say researchers Nick Couldry and Ulises A. Mejias, who describe the "data relations" required to convert "daily life into a data stream":
"data relations enact a new form of data colonialism, normalizing the exploitation of human beings through data, just as historic colonialism appropriated territory and resources and ruled subjects for profit. [...] These new types of social relations implicate human beings in processes of data extraction, but in ways that do not prima facie seem extractive. That is the key point: the audacious yet largely disguised corporate attempt to incorporate all of life, whether or not conceived by those doing it as 'production,' into an expanded process for the generation of surplus value. The extraction of data from bodies, things, and systems create new possibilities for managing everything. This is the new and distinctive role of platforms and other environments of routine data extraction." 13
Datasheets
Datasheets are documents describing each dataset’s characteristics and composition, motivation and collection processes, recommended usage and ethical considerations, and any other information to help people choose the best dataset for their task. Datasheets were proposed by diversity advocate and computer scientist Timnit Gebru, et al., as a field-wide practice to "encourage reflection on the process of creating, distributing, and maintaining a dataset, including any underlying assumptions, potential risks or harms, and implications for use." 14 Datasheets are also resources to help people select and adapt datasets for new contexts.11
MacKenzie, A. 2018. Machine Learners. MIT Press.
Ciston S (2023) “A Critical Field Guide for Working with Machine Learning Datasets."Crawford K and Ananny M, Eds., Knowing Machines project.
Engine Room. (n.d.). Responsible Data Handbook
Gebru T, et. al. (2020). "Datasheets for Datasets,” ArXiv180309010 CS, Mar 2020
E is for embeddings
Embeddings
Embeddings are the complex numerical approximations of words, images, or other media, created in order for them to be processed by computers. For example, word embeddings are created by repeatedly comparing each word (or word fragment) in a document (or large group of documents) to all the other words around it. The frequency with which each word appears near other words is recorded in a matrix, which is repeatedly manipulated and reduced until each word can be represented by a long string of usually hundreds of numbers (word vectors). Those numbers 'represent' the word — but only in the context of the other terms with which it was trained. Many large models use these embeddings to compare words or images to one another or to predict what word or image to produce next in a series. They do this by using the numerical representations to output another appropriate numerical representation (not by understanding as a human might).
F is for features & free software
Feature extraction
Features are the attributes being analyzed, considered, or explored across the dataset, often viewed as a column in a table. Feature extraction and feature engineering are techniques used to focus on the specific information in a dataset that is relevant to the researchers or model designers. They may need to create features (e.g., add columns to a table) to show data from new perspectives. This can impact how the dataset can be analyzed going forward, how the model can be designed, and how the data subjects and subjectees might be affected.
FLOSS
FLOSS stands for Free Libre Open Source Software. Broadly, open source means the dataset or source code is available to be viewed, changed, and used free of charge by the public. In most cases, licenses must be observed that describe how it should (not) be used.15 FLOSS philosophies represent many different approaches to licensing information around the production and distribution of technologies, with a focus on access and permissive use. This has been a positive for many academic and scientific endeavors, but it has also been exploited by many corporate endeavors who build on FLOSS work to develop and profit privately.
Training the Archive. Glossary
Foundation models
See Models
G is for global & generative
GPT
GPT stands for Generative Pre-trained Transformer. It's a type of machine learning model developed first in 2018 that relies on giant collections of unlabeled data. In the case of OpenAI's language generating tools and many others, these data often come from scraped public websites, including Wikipedia, Reddit, GitHub, Smashwords, Flicker, and Project Guttenberg.
Global majority
The phrase 'global majority' (sometimes also referred to as the global south) suggests reframing how we consider the many identities who are left out of conversations and calculations about technologies that impact them, whether because they are treated as 'minorities' or edge cases, or because they have been denied access and resources due to wealth disparity in the global north — often both. Western, educated, industrialized, rich, democratic (W.E.I.R.D.) populations, along with heterosexual, monogamous, white men, are usually treated as the norm when conducting research or creating technologies — against which all others are differentiated. However, the W.E.I.R.D. may average to a middle, but they are not a majority, nor a default. The global majority of people exist in all intersecting variations outside this normalized baseline. What happens when we rethink the design and use of AI systems using new baselines?
"The (largely North led) agenda setting has material implications in terms of which problems are studied, with the limited funding and resources available. However, not only are southern populations more vulnerable to ‘existential’ risk (in part because of their post-colonial contexts), but North-led development of AI perpetuates extractive patterns that exacerbate these vulnerabilities."16
Singh A, Vale D. 2021. "Existential Risk." A New AI Lexicon.
GAN
GAN stands for generative adversarial network and is a now-popular kind of machine learning used to generate new data, such as images seen in the "AI dreaming" aesthetic. It requires two parts: One part is trained on existing data in order to check the second part's work. The second part is trying to generate new data that can fool the first part (hence adversaries).
H is for heteronormative
Heteronormative
"Attitudes and behaviors that incorrectly assume gender is binary, ignoring genders besides women and men, and that people should and will align with conventional expectations of society for gender identity, gender expression, and sexual and romantic attraction".
–UC Davis LGTBQIA Resource Center,17 cited by Studio Pathways Glossary6
Normative categories affect AI because they impact how computational systems are designed and implemented. For example, if a survey is designed with only two choices for gender, or if a programming language uses only true and false to encode those choices, machine learning models trained on data from that survey will present already limited viewpoints. They will not be able to account for survey takers who did not fit in those two choices, nor be able to account for viewers of the machine learning outputs who do fall outside of those choices either. Despite no explicit decision being made to exclude anyone, many people end up not represented by using normative lenses alone.
I is for Intersectionality
Intersectionality
"Intersectionality, as first named by Kimberlé Crenshaw (1989), center[s] interlocking systems of oppression and in doing so make[s] visible the normative value systems that facilitate erasure."18
In Kimberlé Crenshaw’s original formulation of intersectionality, which originated in her legal scholarship and has been expanded broadly, intersectionality analyzes differences in structural power and how it operates at scale. It is not only about individuals' identities but about how multiple forms of discrimination have compounding, interdependent effects. She argues that intersectional analysis is critical for examining both discrimination and privilege, as these are two aspects of the same systems. 19 Intersectional methods are essential for addressing bias and power in AI, because they draw on important work by a wide range of communities — Black feminists, queer and disabled theorists, and others — who have been considering difference and equitable systems for decades before these questions became digital.
Gipson, B., Corry, F., & Noble, S. U. (2021). Intersectionality. In Uncertain Archives: Critical Keywords for Big Data. https://doi.org/10.7551/mitpress/12236.003.0027
Crenshaw, K. (1989). Demarginalizing the Intersection of Race and Sex: A Black Feminist Critique of Antidiscrimination Doctrine, Feminist Theory and Antiracist Politics. University of Chicago Legal Forum, 1989, 139–168. ———. (2021, March 29). What Does Intersectionality Mean? : 1A. https://www.npr.org/2021/03/29/982357959/what-does-intersectionality-mean
J is for Justice
Justice, transformative
Rather than punitive justice as practiced by governments, which punishes or removes people from their communities who perpetuate harm, transformative justice is a way to respond to violence and harm within our own communities that avoids reproducing harm and instead to seeks to repair as well as to address the root of problems, so that the conditions which created the issue cannot be repeated.20
"How do we change, heal, transform so that this harm is no longer possible? How do we understand that the state is committed to punitive justice and transformative justice is not possible from the state?" 20
What is Transformative Justice? (2020, March 5). Barnard Center for Research on Women. https://bcrw.barnard.edu/videos/what-is-transformative-justice/
K is for K
K-Means & K-Nearest Neighbor (KNN)
K-Means and K-Nearest Neighbor are two commonly used algorithms for machine learning. The k represents something different in each, and their process of grouping information is also different. K-Means separates into groups. It finds patterns by clustering an unlabeled set of data into a selected number (k) of categories (see "Unsupervised" in Supervised & unsupervised). In contrast, K-Nearest Neigbhors sorts like with like. It categorizes new data based on similarity to existing data, by looking for a selected number (k) of closest nearby datapoints (see "Supervised" in Supervised & unsupervised).
L is for Lynn

Lynn Conway
Lynn Conway is a prominent computer scientist who is known for designing innovations in supercomputers and very large-scale integrated circuits. In 1968 she was fired from IBM for notifying them she would be undertaking gender transition. In 2000, after 52 years in an extremely successful career at Xerox PARC, Memorex, and University of Michigan, she received a formal apology from IBM.
M is for models & machines
Machine learning
Machine learning is a set of tools used by computer programmers to find a formula that best describes (or models) a dataset. Whereas in other kinds of software the programmer will write explicit instructions for every part of a task, in machine learning, programmers will instruct the software to adjust its code based on the data it processes, thus "learning" from new information. Its learning is unlike human understanding and the term is used metaphorically. Due to their increasing complexity, the outputs of machine learning models are not reliable for making decisions about people, especially in highly consequential cases. Include machine learning as one suite of options in a broader toolkit — rather than a generalizable multi-tool for every task.11
Model
Models are the result of the processes of machine learning, once it includes revisions that take into account the data it was exposed to during its training. It is the saved output of the training process, ready to make predictions about new data. One way to think of a model is as a very complex mathematical formula (algorithm) containing millions or billions of variables (values that can change). These variables are designed to transform the numerical input into the desired outputs. The process of model training requires adjusting the variables that make up the formula until the output matches the desired output. Much focus is put on machine learning models, but models depend directly on datasets for making their predictions.11 Increasingly, models are trained using on top of other 'foundation models'. These popular models were originally trained with a broad scope of data, with the intention of making them widely adaptable for many uses; however, because they are so large and because they get folded repeatedly into new models and new contexts, this makes their results harder to understand and potentially more fraught 21.
"Reflections on Foundation Models." 2021. Stanford Human-Centered Artificial Intelligence. October 18, 2021. https://hai.stanford.edu/news/reflections-foundation-models
N is for 'neural'
Neural network
Neural networks describe some of the ways to structure machine learning models, including large language models. Named for the inspiration they take from brain neurons (very simplified), they move information through a series of nodes (steps) organized in layers or sets. Each node receives the output of the previous layers' nodes, combines or processes them using a mathematical formula, then passes the output to the next layer of nodes.11
O is for opacity
Opacity
Rather than more data and more transparency, many people who bare the brunt of the harmful impacts of machine learning systems like facial recognition have been arguing for the right not to be included in datasets (opt-out) and for the right to have their information removed from systems (sometimes referred to as machine unlearning). For much longer than there has been AI, Black activists and scholars have been arguing for alternative perspectives than totalizing approaches that demand to 'know' in in ways that capture and reduce bodies, difference, and freedom:
"If we examine the process of 'understanding' people and ideas from the perspective of Western thought, we discover that its basis is this requirement for transparency. In order to understand and thus accept you, I have to measure your solidity with the ideal scale providing me with grounds to make comparisons and, perhaps, judgments. I have to reduce. [...] "—But perhaps we need to bring an end to the very notion of a scale. Displace all reduction. Agree not merely to the right to difference but, carrying this further, agree also to the right to opacity that is [not enclosure within an impenetrable autarchy but] subsistence within an irreducible singularity. Opacities can coexist and converge, weaving fabrics. To understand these truly one must focus on the texture of the weave and not on the nature of its components. For the time being, perhaps, give up this oid obsession with discovering what lies at the bottom of natures. There would be something great and noble about initiating such a movement, referring not to Humanity but to the exultant divergence of humanities. Thought of self and thought of other here become obsolete in their duality. Every Other is a citizen and no longer a barbarian. What is here is open, as much as this there. I would be incapable of projecting from one to the other. This-here is the weave, and it weaves no boundaries." Édouard Glissant [-@glissantPoeticsRelation2009a]
Overfitting & underfitting
See Bias & variance
P is for peers & protocols
Protocol
A protocol is a set of well-defined rules for how data is sent between computers. 22
Peer-to-peer
In peer-to-peer networks, there is no central authority. Rather each machine acts as a server offering content to the others.22 This model could be aligned with mutal aid networks and other decentralized systems built outside of big (government or corporate) infrastructure platforms.
Q is for queer
Queer OS
"Queer OS," as theorized by Black film scholar Kara Keeling, names a way of seeing queerness and gender as technologies and a way of seeing and using technologies [queerly/as queer infrastructure], "to facilitate and support imaginative, unexpected, and ethical relations between and among living beings and the environment, even when they have little, and perhaps nothing, in common." Keeling positions a Queer OS as an operating system at the social level and computational level, which reconfigures power based on queer values: "Because Queer OS ideally functions to transform material relations, it is at odds with the logics embedded in [existing] operating systems [.... It] seeks to undermine the relationships secured through those logics, even as [...] it acknowledges its own imbrication with and reliance on those logics while still striving to forge new relationships and connections."24
Keeling, K. (2014). Queer OS. Cinema Journal, 53(2), 152–157. https://doi.org/10.1353/cj.2014.0004
R is for regression & racialization
Racialization
Structural racism: A system in which public policies, institutional practices, cultural representations, and other norms work in mutually reinforcing ways to perpetuate racial group inequity. A structural analysis of racism identifies dimensions of our history and culture that have allowed privileges associated with "whiteness" and disadvantages associated with "color" to endure and adapt over time. Structural racism is not something that a few people or institutions choose to practice. Instead it is a feature of the social, economic and political systems in which we all exist. –Mimi Onuoha and Mother Cyborg (Diana Nucera), A People's Guide to AI[^Onuoha]
Racialization: "Processes of racialization begin by attributing racial meaning to people's identity and, in particular, as they relate to social structures and institutional systems, such as housing, employment, and education." –Encyclopedia of Race, Ethnicity, and Society, via Studio Pathways6
Regression & classification
Regression tasks show the relationship between features in a dataset through ordering them based on a selected feature or features, for example sorting dogs by their age and number of spots. These are distinguished from classification tasks, which label and sort items in a dataset by discrete categories. For example, asking whether an image is a dog or a cat is handled by a classification task.11
S is for sustainability & supervision
Supervised & unsupervised
In supervised machine learning techniques, at least a portion of the training data will already indicate the patterns that the model is designed to "learn." Unsupervised machine learning techniques also find patterns, but these are not already labeled in the dataset. They different kinds of machine learning techniques, such as clustering groups of data together by the features they share. However, don't think that conclusions drawn from unsupervised machine learning are somehow more pure or rational. Just as much human judgment goes into developing unsupervised machine learning models as supervised ones. Often supervised and unsupervised approaches are used in combination to ask different kinds of questions, or techniques are used that are somewhere between the two approaches. 11
Sustainability
Is AI sustainable? Creating and using AI systems accumulates huge environmental impacts. The ease with which we can get quick, if fallible, answers from systems like ChatGPT obscures their resource-hungry consumption, like the bottles of water consumed with every few queries and the electricity needed to power their training and keep their data centers cool. Considering "environmental justice" as a more complex intersectional lens can help us wrestle with the harms of large technical systems. This includes but goes beyond quantifying AI systems' impacts, which are disproportionate across categories of difference like class, race, and gender. "Reframing sustainability and AI in terms of environmental justice offers a way to center the material contexts and implications of AI technologies and provides a framework for imagining community-led, socially just futures."25
Rachel Bergmann & Sonja Solomun. 2021. AI Now's A New AI Lexicon: Sustainability
T is for trans
Transformer
A transformer is a common structure for current machine learning models, including GPT. They are designed to digest huge datasets of unsorted text, images, audio, or video. Those input data are converted into numerical form based on their relationship to nearby word fragments or pixel values, for example (see values). These processes are repeated many times to 'encode' the numbers and to 'normalize' or standardize those numbers in relation to each other. Then the process can be repeated to 'decode' data and return an output in the form of text, image, audio, or video. At each stage the designers can control what passes through the model with filters called 'activation functions', and additional information be used to 'weight' the existing information, or to focus it toward a new topic.
U is for un
Uncertainty
Louise Amoore argues that the output of an AI system is never simply either true or false, but an effect of relations, a series of optimized probabilities, eventually labeled as a certainty. She says, "Where politics expresses the fallibility of the world and the irresolvability of all claims, the algorithm expresses optimized outcomes and the resolvability of the claim in the reduction to a single output."[^Amoore] Further, she argues that these systems are "geared to profit from uncertainty, or to output something that had not been spoken or anticipated."[^Amoore] However, uncertainty remains at every point in the process, says Amoore:
"Though at the point of optimized output, the algorithm places action beyond doubt, there are multiple branching points, weights, and parameters in the arrangements of decision trees and random forest algorithms, branching points at which doubt flourishes and proliferates."[^Amoore]
V is for values, variables, vectors, oh my!
Values
Values are the perspectives and ethics each person and community holds which determine how they act and how they evaluate situations, what they protect and who they esteem (and don't). Values are embedded in and expressed by technologies because they are designed and produced by people who hold values and make decisions based on those values, whether consciously or unconsciously. Values are also a term for information that can be represented as numbers or strings of text. On a social media profile, your age may be a value in a dataset that also includes values like your username, password, and personal interests that are of use to advertisers.
Variables
Variables are labeled containers for information. They are placeholders you can name and store values in to recall for later. Let's say let x = 1. That means we declared x is a variable storing the number 1. Later we can ask, "What was x?" or say, "Change x = 3 now." (And then next time we ask what x equals, the answer will be 3.) This allows information to be moved through a program and manipulated. By combining lots of variables and processes, programmers can perform powerful manipulations of large amounts of data.
This naming has power. As a programmer, you decide what to name your variables, and you decide how your systems are organized and structured. That means you decide what information means, whether it is the weight of a feature in a machine learning model or the threshold that separates one color from another. These decisions matter and are informed by your values.
Vectors
Vectors are lists of numbers used for machine learning calculations. Sometimes called arrays, these lists of numbers can be compared with each other and can be graphed in space to understand the relationships among the data they represent. You might remember plotting [x,y] coordinates in a geometry class. Imagine plotting vectors coordinates with many more dimensions [x,y,z,...], sometimes hundreds. Vectors are often used in machine learning tasks to represent words, images, and other media, for example as word embeddings.
W is for
(bag of) Words
"Bag of words" is a natural language processing method of analyzing and classifying text that looks only at the frequency each word occurs, while disregarding the order of the words, syntax, or grammar — as if the words were all thrown in a bag. In current approaches to creating word embeddings (see E is for embeddings), the "continuous bag of words" (CBOW) technique is used to predict a single word given a set number of surrounding words for context. In contrast, the "skip-gram" technique tries to predict the context words given a set number of input words.
X is for X (input)
X (input)
"Garbage in, garbage out" the saying goes. How datasets are created, shaped, and implemented as training input for AI systems fundamentally informs their resulting outputs. Datasets are not the only element affecting how AI works, but they are a key element in all AI systems. To dive deep into datasets, see A Critical Field Guide for Working with Machine Learning Datasets, which is a friendly introduction, defining all the types and parts of datasets, all the benefits and pitfalls of how to use datasets practically and critically.
Y is for output ... YOLO!
Y (output)
y = f(x) + Σ the simplest machine learning model looks like this. Don't be afraid of the math — it's shorthand like you might have learned in high school. Written out in words, it means that the output or results of a model is function f(). A function just means that some calculation (algorithm, operation, recipe) is performed on the stuff inside ( ). Here we see a function of some inputs x (which are known, and are also called parameters or features) plus the error Σ (which is unknown). It is adjusted based on what the model's creators determine will yield expected, "appropriate" results.
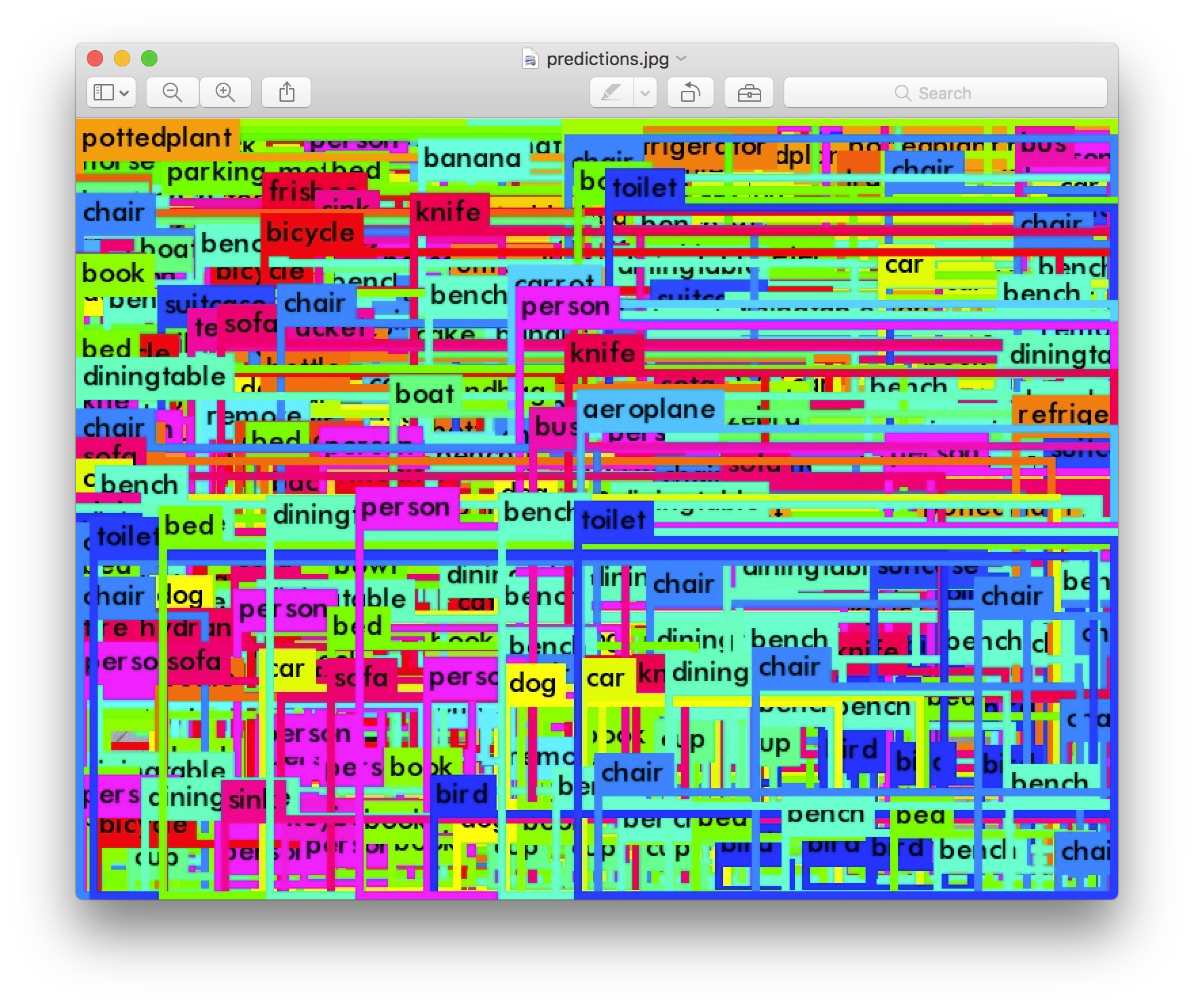
YOLO
"You Only Look Once" (YOLO) is a popular computer vision algorithm used for real-time and multiple object detection and classification. It identifies and labels items in still and moving images, and it has been applied to self-driving cars and surveillance. YOLO is an example of a convolutional neural network (CNN) that finds patterns in the number representations of image pixels. As the network layers accumulate, the patterns get more complex and it is trained to categorize these patterns into objects based on labels it is given in advance. 26 The YOLO9000 system, for example, was trained on prior datasets like ImageNet (itself a highly contested dataset) for its classification labels and on COCO for detection.
Redmon J, Farhadi A. 2016. "Yolo9000: Better, Faster, Stronger"
Z is for
Zero-shot learning
Usually, machine learning systems are trained by being exposed to tons of examples, but in few-shot or zero-shot learning, they are designed to output desired results without being previously exposed to that category of information. It is becoming more common in recent "generalizable" models that are supposed to work for many kinds of purposes and topics. It operates by inferring from information in other categories and fields of knowledge.
Zines
Zines, short for 'magazines', are publications that come in many print and digital forms. Often self-published, they can be photocopied and stapled or elaborately constructed. They have a history rooted in diverse politics and perspectives. Some of our favorite zines are collected by Tiny Tech Zines. Read more writing about the history and variety of zine culture in these books and articles:
- Duncombe, S. (2008). Notes from underground: Zines and the politics of alternative culture. Microcosm Publishing.
- Hono, M. (2021). Scrappy Messiness Increases Affection – Zines as Rebellion Against the Cultural Dominance of Digital Self-Publishing. https://you.stonybrook.edu/zines/scrappy-messiness-increases-affection/
- Oakley, B. (2023). Imperfect Archiving, Archiving as Practice: The Ethics of the Archive. GenderFail.
- Piepmeier, A. (2008). Why Zines Matter: Materiality and the Creation of Embodied Community. American Periodicals, 18(2), 213–238.
- Simanjuntak, R., Espinoza, T., & Yin, T. Tiny Tech Zines. http://tinytechzines.org/